

Your First Line of Defense Against Fraud
The Device-First Risk AI Platform that Stops Fraud at Its Root
Trusted By











Trusted by
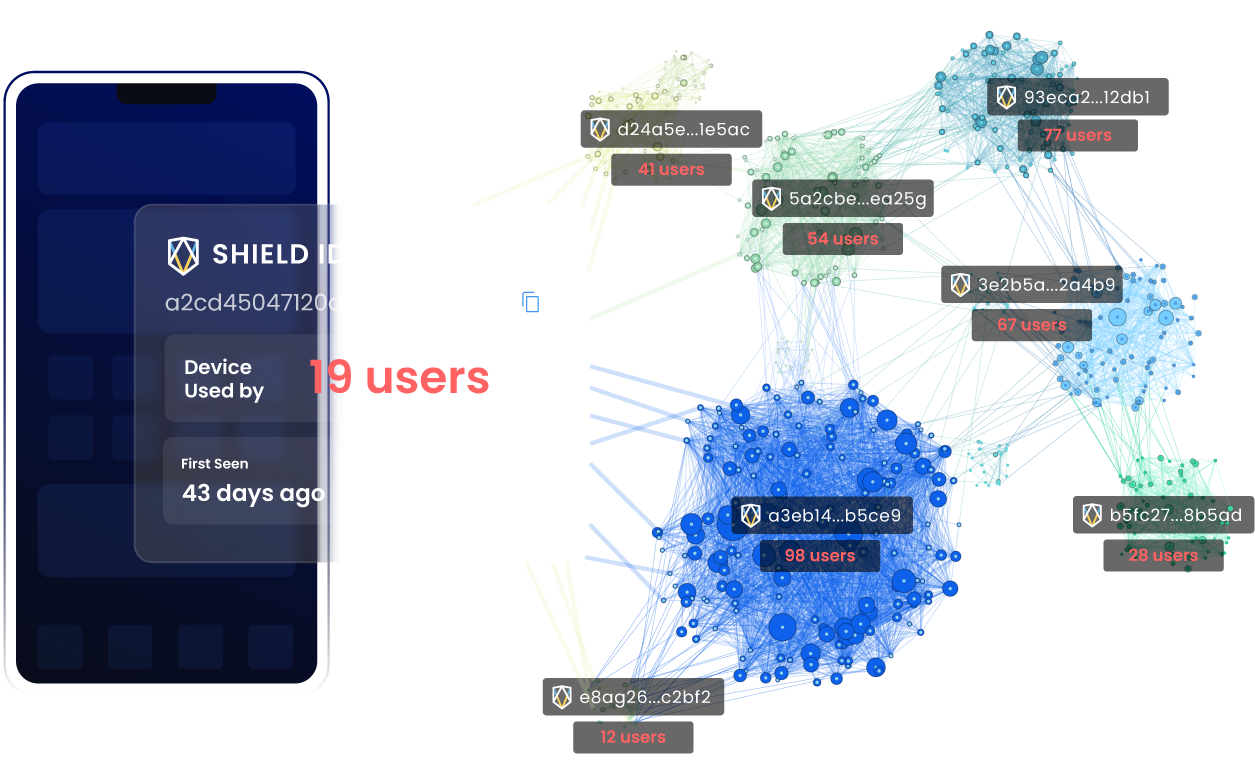


Instant insights. No additional codes needed. Gain intelligence without giving PII data.

Self-configurable risk thresholds. We return all data, and more. Get the full picture with transparent intelligence.

Stay ahead of new and emerging fraud attacks. Real-time attack pattern syncing worldwide.


“inDrive is dedicated to challenging injustice and upholding transparency and fairness in the mobility and transportation space. Our partnership with SHIELD empowers us to stay true to our mission of helping people, ensuring the highest standards of trust and fairness for all while maintaining our rapid pace of growth.”
Arsen Tomsky
CEO & Founder, inDrive


“SHIELD’s Device Intelligence, the first fraud prevention Unity plugin, is a gamechanger for the industry. By leveraging this cutting-edge technology, we can confidently ban cheaters without affecting legitimate users, building user trust in the ample opportunities that the metaverse offers.”
Sami Khan
Co-Founder and CEO, Atlas Reality


"Customer trust is our top priority and SHIELD is the best technology to guarantee this."
Monsinee Nakapanant
Co-President, Ascend Money


“SHIELD’s technology has provided us with risk intelligence to secure our platform - a quintessential element for all skill gaming providers. With SHIELD, we can safely say that we are the most trusted online gaming platform in India.”
Arpit Beniwal
Head of Product, Baazi Games


“Providing the highest degree of protection against fraud is top priority at MPL. We are focused on offering users a safe and secure gameplay experience on our app. In order to deliver this consistently, we are committed to using best-in-class technology. Our partnership with SHIELD has enabled us to continue to take this forward ”
Ruchir Patwa
Vice President, Security and Compliance, MPL

“The security of our users is of paramount importance to us. While we have a solid in-house infrastructure and tech stack, SHIELD's Device Intelligence complements our efforts to further drive and scale credit inclusion in a safe and secure manner.”
Natalia Lyarskaya
Chief Data Officer, ZestMoney


















